

Image classification is a means of satellite imagery decryption, that is, identification and delineation of any objects on the imagery. Classification is an automated methods of decryption. The user does not need to digitize the objects manually, the software does is for them.
According to the degree of user involvement, the classification algorithms are divided into two groups: unsupervised classification and supervised classification.
There are several stages of supervised classification:
- determining the number of classes and their contents
- creating training samples
- quality control of training samples
- selecting the classification algorithm (method)
- performing classification
- post-classification map processing
- evaluating the classification accuracy
In this post, we will have a look at how to choose a suitable means of supervised classification. Modern satellite image classification software packages provide a wide choice of algorithms for supervised classification. So each user has to face a question – which is the best among the algorithms? But there is no simple answer to this question. No algorithm is effective in all possible cases. Instead, each method has its own scope. One can determine the best classification algorithm by trying out each of them, to assess the accuracy of the results, and then pick the method that gives the best results. But it can be a lengthy process, especially if we process images of large volume.
To choose the right classification algorithm for you, you need to understand the mathematical bases of algorithms. With this understanding, when you can know when to use or not to use any classification algorithm. But not all users have a good mathematical training. So, we have prepared a diagram to make algorithm selection easier. This diagram shows some of the most common tools for supervised classification. Namely they are (see Fig. 1):
parallelepiped classification,
minimum distance classification,
Mahalanobis distance classification,
binary encoding classification,
and maximum likelihood classification.
In the diagram, go from top to bottom, answering questions by choosing one of two answers. Let’s examine the content of the diagram and see specific examples of selecting a classification method.

Figure 1. Choosing the right classification algorithm
First of all, we need to see how many classes need to be classified. If there only need to be two classes and all the pixels of the image will be assigned to one of them, the best method is binary encoding classification. A typical example of this situation is shown in Figure 2. A fragment of Landsat 5TM image from August 16, 2010 (combination of bands 7:5:3) is shown to the left. It covers a territory of wetlands in the delta of Dnieper river. We need to decrypt water and land classes. For this, two training sets are chosen. Figure 2 (centre) shows training regions in blue and green.

Figure 2. Binary encoding classification use example
Resulting image after binary encoding classification is shown to the right in Figure 2. Here, note that all image pixels were divided between two classes. If extra objects were present in the image that should have been attributed to the unclassified pixels, we would need to use a different classification algorithm.
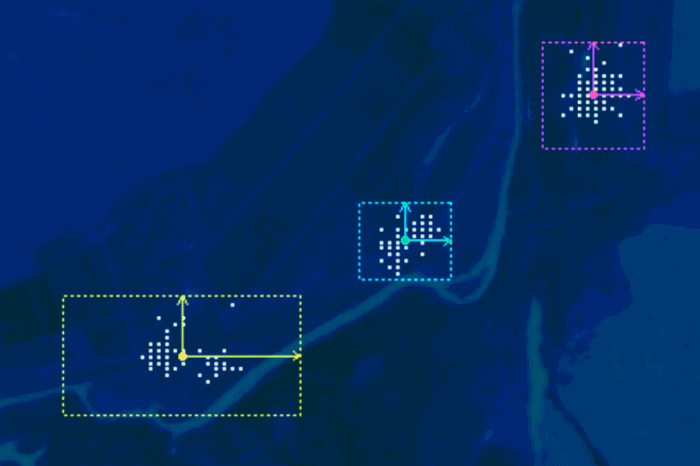
If we need to assign pixels to more than two classes, then for choosing the right method it is necessary to analyze the position of classes in the multidimensional feature space. In ENVI, the process of working with n-D Visualizer is described in a previous post. Possible positions of point clouds of different classes are shown in Figure 3 (in this example we use two-dimensional space of spectral features). Each of these options has its most effective method of supervised classification.
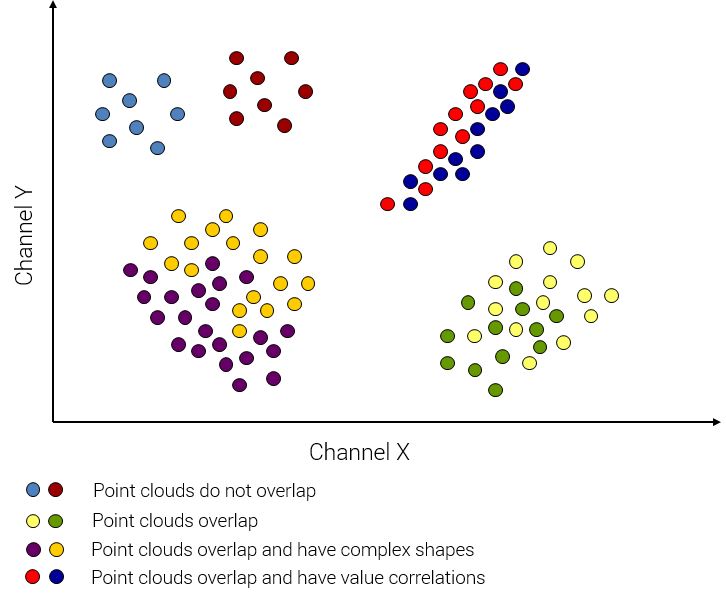
Figure 3. Possible class point cloud locations in n-D feature space
First, we need to check if there are overlaps between class cloud locations. In case the spectral characteristics do not overlap in the feature space, parallelepiped classification can be used. This often it happens when we assign pixels to a small number of classes that belong to fundamentally different types of surfaces. For example, when we classify water bodies, vegetation, soils, surfaces of artificial materials, rocks. Usually these types of objects have very different spectral reflectance capacity. An example is shown in Figure 4.
In Figure 4 (left) we see a portion of Landsat 5TM images from April 26, 1986 (band combination 4:5:3). It covers an area of floodplains and terraces near Seversky Donets river, which extends below the city Chuhuiv. Training areas are selected (Fig. 4, right). They correspond to coniferous forests (green sample), water surface (yellow sample), open terrace on the sand (blue sample), herbaceous vegetation on sandy terraces (red sample) and deciduous woods (blue sample). In Figure 4 (below) we can see the location of point clouds of the samples in the multidimensional space of spectral features. None of the samples interfere with any other. This indicates that the best algorithm to classify images is the parallelepiped algorithm.
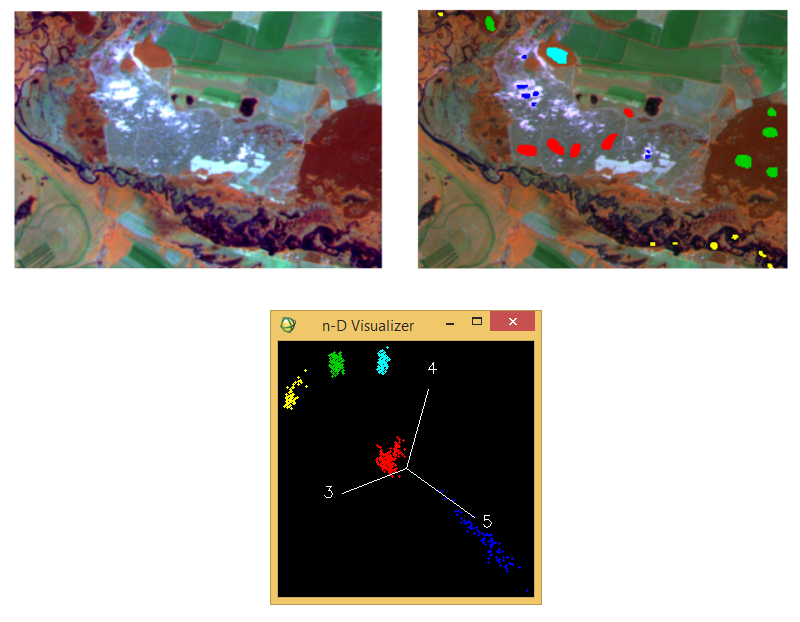
Figure 4. Example of when parallelepiped classification is most suitable
In case the point clouds of classes intersect it is necessary to analyze their shape. It can be simple or complex. We can say that we have a simple shapes of point clouds when they are similar to a sphere or an ellipsoid. When it is anything like an amoeba, it is a complex shape. In case the clouds have complex shapes, the most efficient classification algorithm will be the Mahalonobis distance classification.
If the point clouds have simple shapes that overlap, we must determine whether there is a correlation between the brightness in different ranges of the spectrum or not. To see about this correlation we need to look at the point cloud shape in the feature space. If it is complex, then, of course, there is no correlation there. That issue may be relevant only to simple shapes of clouds of values. When this form is perfect sphere – no correlation there. And if the cloud has the shape of an ellipsoid, the correlation does exist. The more flattened and elongated the ellipsoid, the higher the correlation.
In cases where there is a correlation between the brightness in different ranges of the spectrum, is best to use maximum likelihood algorithm. And if it is not present – the minimum distance classification.
An example of minimum distance classification case is shown in Figure 5. On the left we see a fragment of Landsat 5 TM image taken on September 26th, 2009 (band combination 7:5:3). It covers a floodplain near Vorskla river and the area around it. This location lies south of Okhtyrka and partly belongs to “Hetmanskyy” national park.
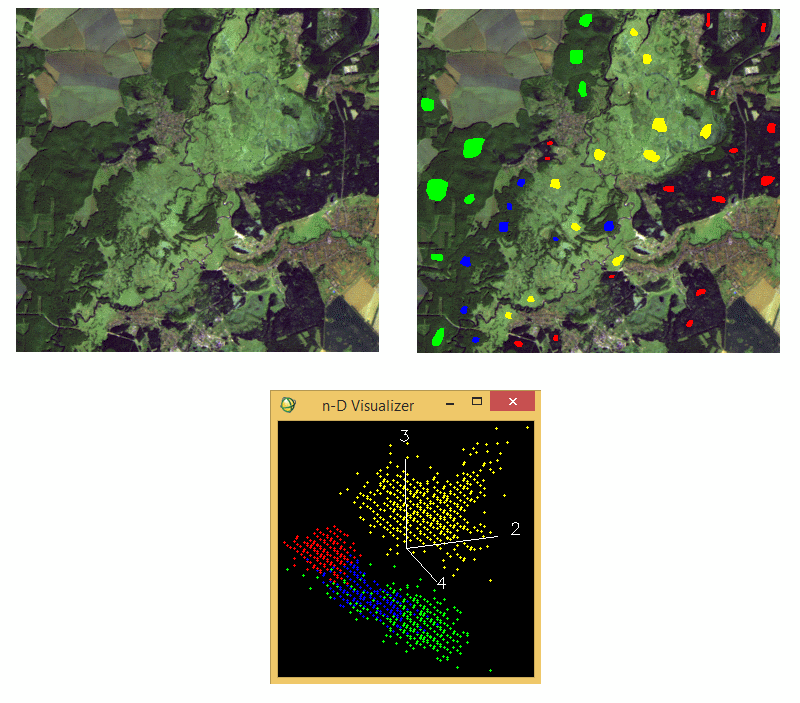
Figure 5. A case when minimum distance classification is used
The aim of classification is to separate pixels of various vegetation types. Four training samples are selected in the image, Figure 5 (right). They are grassy floodplain vegetation (yellow sample), coniferous forest (red sample), deciduous forests (green sample) and small-leaved floodplain forests (blue sample). Spectral characteristics’ feature space is shown at the bottom of Figure 5. In it we see three point clouds of the sample values, they intersect. These clouds have simple shapes. This indicates that the best image can be classified by the minimum distance algorithm.
And now to an example of the maximum likelihood classification algorithm case (Figure 6). On the left side Landsat 7 ETM+ image from August 8th, 2001 (band combination 7:5:3) is shown. It covers the area along Morka Sura river near its confluence with Dnieper river. Here the aim is to monitor burning of stubble. To do this, we need to identify the following classes: stubble fields, fields with stubble burned, fields with bare (plowed) soil and green vegetation. These classes correspond to yellow, red, green and blue samples (Fig. 6, right).
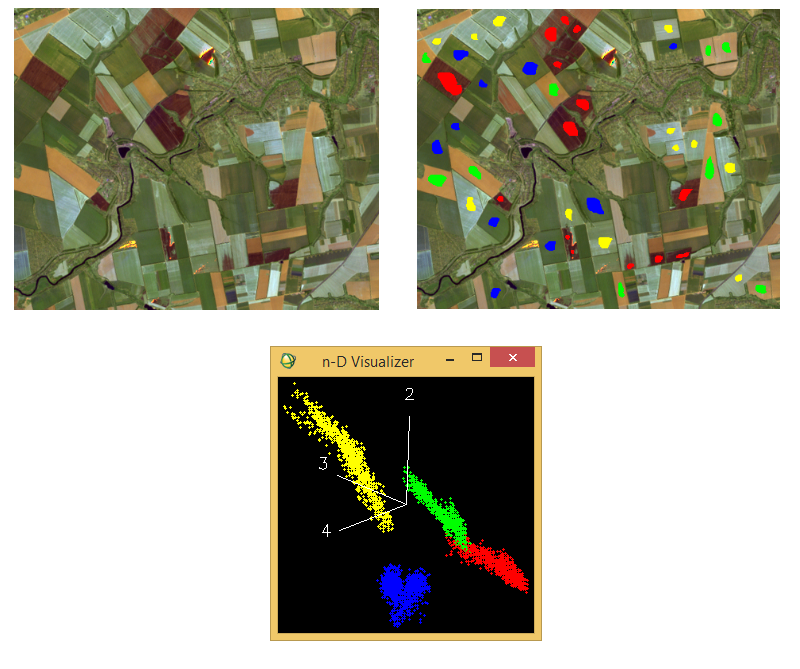
Figure 6. Maximum likelihood classification case example
Figure 6 (bottom) shows the spectral feature space. In it we see that the two value clouds are overlapping. In addition, three clouds have prolonged shape. This indicates that we need to classify the image using the maximum likelihood algorithm.
Finally, an example of Mahalanobis distance classification use is shown in Figure 7. A fragment of Landsat 5TM satellite image from October 8th, 2011 (band combination 4:5:3) is on the left. The image covers an area around Seversky Donets river, south of Belgorod reservoir. In this scene we need to distinguish three classes: coniferous forests, deciduous forests and herbaceous vegetation. On the right, the training samples for these classes are respectively green, red and blue.
Considering the spectral feature space (Fig. 7, bottom), we see that the sample value clouds overlap. In addition, the “blue” sample has a complex shape like a “swallow’s tail”. Mahalanobis distance algorithm is best to be used in such a case.
It should be noted that in previous examples the brightness values point clouds for herbaceous vegetation had nearly simple shapes (Fig. 4, Fig 5). In this case, it is the opposite. It so happened that herbaceous vegetation in the image is more varied, it contains both dry and floodplain vegetation.

Figure 7. Mahalanobis distance classification case example

Thus we have looked at how to choose a suitable supervised classification algorithms for different situations. The last case is a good example that the same type of objects does not have a universal classification algorithm, which will always be effective. For each case it is necessary to investigate point clouds of class values in the multidimensional spectral feature space.



Дуже дякую за якісну статтю. Саме сьогодні зіткнувся із завданням автоматизованого дешифрування.
На практиці зазвичай доводиться робити класифікацію в кілька етапів (так звана гібридна класифікація). Класифікація за один раз це швидше виняток. Плюс щоб отримати хороший результат треба робити постобробку.
Дякую за цікаву статтю. Але як би ж то так все просто було: зазвичай всі класи так змішуються, що взяти і відкласифікувати одним махом не виходить. Завжди додаткові танці. Це риторично-ліричне зауваження було.
А практичне – варто гарно продумувати навчальну вибірку, її величину та репрезентативність, аналізувати на нетипові значення, а тоді вже досліджувати з позиції вибору методу класифікації. Пару “вильотів” і картинка розподілу у просторі ознак буде спотвореною.